Sheet 3
††course: Optimization in Machine Learning††semester: FSS 2023††tutorialDate: 30.03.2023††dueDate: 12:00 in the exercise on Thursday 30.03.2023Exercise 1 (Convergence Speed).
Proof that
-
(i)
if we have
then converges super-linearly.
Solution.
We define . Then
and by definition
Thus we have super-linear convergence. ∎
-
(ii)
If for we have
then converges linearly with rate .
Solution.
We again define
thus there exists such that for all we have and therefore for all
-
(iii)
If for we have
then converges super-linearly with rate .
Solution.
We similarly define and again get . Thus there exists such that for all we have and therefore for all
Exercise 2 (Sub-gradients).
Let be convex functions.
-
(i)
Prove that is a convex set for any .
Solution.
Let . Then for any and any
≥λ(f(x) + ⟨g_1, y-x⟩) + (1-λ) (f(x) + ⟨g_2, y-x⟩) thus by definition. ∎
-
(ii)
Prove for ,
Solution.
We only need to prove “”. Using with the other inclusion immediately follows.
Let with . We need to show that . But this follows immediately
-
(iii)
Prove that
Solution.
Let for . Then we have that because
-
(iv)
For prove . Prove equality for invertible .
Solution.
Let i.e. . Then because
If is invertible, we have so by the previous statement with and , we get the other direction. ∎
Exercise 3 (Lasso).
Let
for be the Lagrangian form of the least squares LASSO method.
-
(a)
Compute a sub-gradient of .
Solution.
Using , we only need to determine the subgradient of and
But as is differentiable. And since it is also convex, we have
Now the subgradient of is given by , where can be selected arbitrarily, because
So again
So putting everything together we have
-
(b)
Prove that is convex.
Solution.
As its sets of sub-gradients is nowhere empty, it is convex. ∎
-
(c)
Find a global minimum of .
Solution.
By the lecture it is sufficient to find a point such that . By the previous exercise we therefore want to solve
entry-wise this implies
= y_i - λsgn(x_i) = { y i + λ x i ¡ 0 y i - λ[-1, 1] x i = 0 y i - λ x i ¿ 0 -
(d)
Implement as a sub-type of ”DifferentiableFunction” (even though it is not) by returning a single sub-gradient and apply gradient descent to verify the global minimum https://classroom.github.com/a/XqNuifmO .
Exercise 4 (Momentum Matrix).
let , and define
Prove there exists a regular such that
with
Solution.
We simply define for the standard basis
in particular . ∎
Exercise 5 (PL-Inequality).
Assume is -smooth and satisfies the Polyak-Łojasiewicz inequality
(PL) for some and all with .
-
(I)
Prove that gradient descent with fixed step size converges linearly in the sense
Solution.
By -smoothness and the descent lemma, we have
Subtracting from both sides, we get
-
(II)
Prove that -strong-convexity and -smoothness imply the PL-inequality.
Solution.
Recall by the solution of sheet 1, exercise 6 (iii), and strong convexity we have
and therefore
(1) Finally we know by -smoothness and where is the minimum
-
(III)
Use a graphing calculator to find such that satisfies the PL-condition (argue why is not a problem) and prove it is not convex.
Solution.
For we have the PL-condition
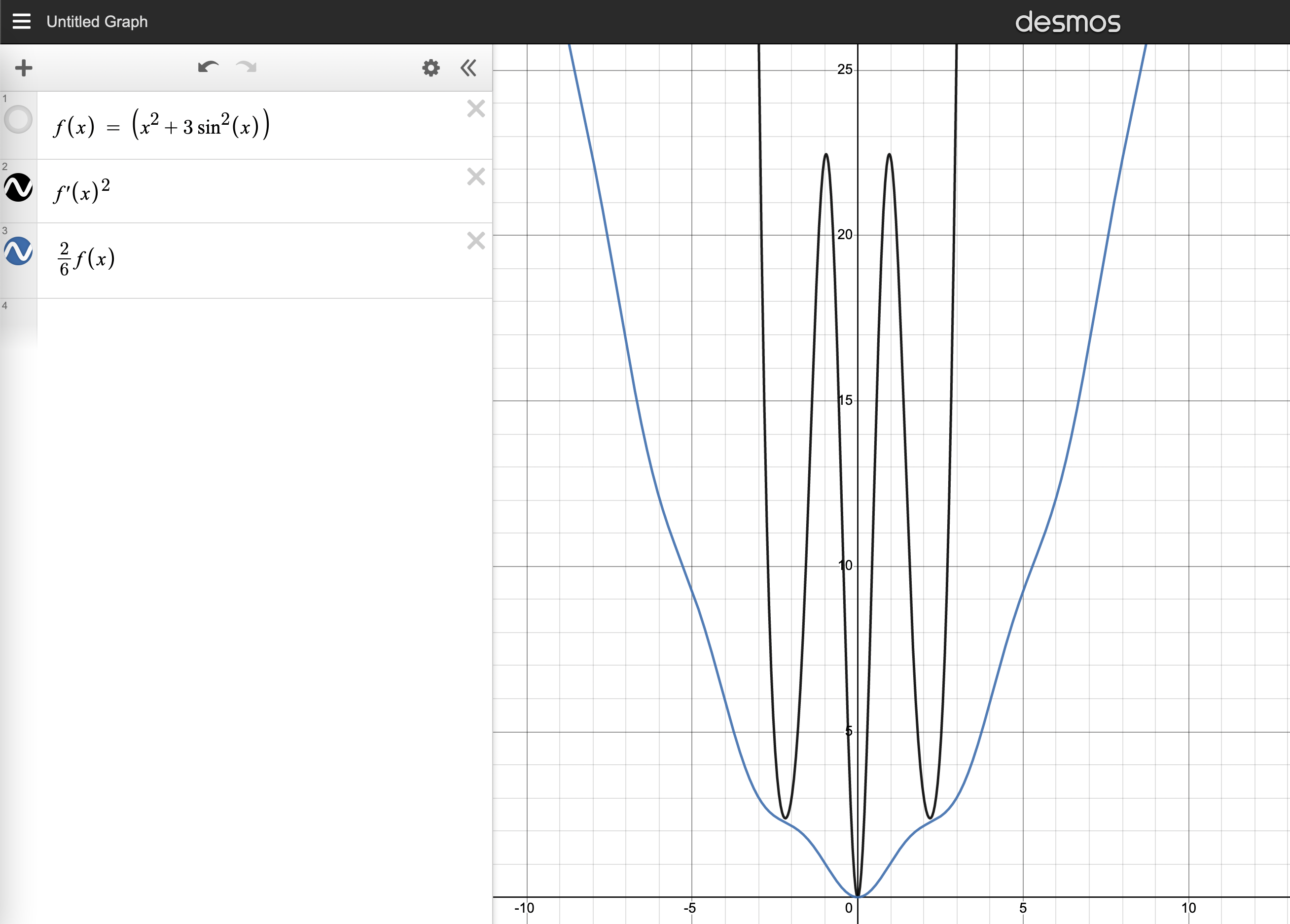
As and therefore
the dominates for large , so if we make small enough we can ensure the inequality for large .
is not convex because
∎
Exercise 6 (Weak PL-Inequality).
Assume is -smooth and satisfies the “weak PL inequality”
for some and all with .
-
A.
Let for some and assume for the sequence that it is positive and satisfies a diminishing contraction
Prove the convergence rate
Hint.
A useful checkpoint might be the telescoping sum of
Solution.
Divide the reordered contraction
by to obtain
which leads to
Reordering we obtain our claim
-
B.
Prove that is bounded. More specifically for all .
Hint.
Use Sheet 1 Exercise 1 (i).
Solution.
Using Sheet 1 Exercise 1 (i), we get
and therefore
Dividing both sides by we obtain
and thus
-
C.
For gradient descent with constant step size prove the convergence rate
Solution.
Using -smoothness, we have
If we subtract from both sides and apply our weak PL inequality we get
with and by (iv)(III)B, we can apply (iv)(III)A to obtain our claim. ∎
-
A.
-
(I)
-
(a)